我做了一个视频总结原型:把长视频变成可追问的笔记

我做这个项目的起点很简单:我经常会遇到一些“很想看,但又确实太长”的视频。
有些是 B 站科普,有些是 YouTube 技术分享,有些是访谈、发布会、课程或者播客。它们往往不是没有价值,而是价值被埋在几十分钟甚至几个小时的时间线里。真正让我想动手做一个工具的瞬间,是我发现自己并不总是想“看完视频”,我更多时候只是想先知道:
- 这个视频到底讲了什么?
- 哪几段值得认真看?
- 有没有我关心的问题?
- 如果我继续追问,它能不能基于原视频内容回答?
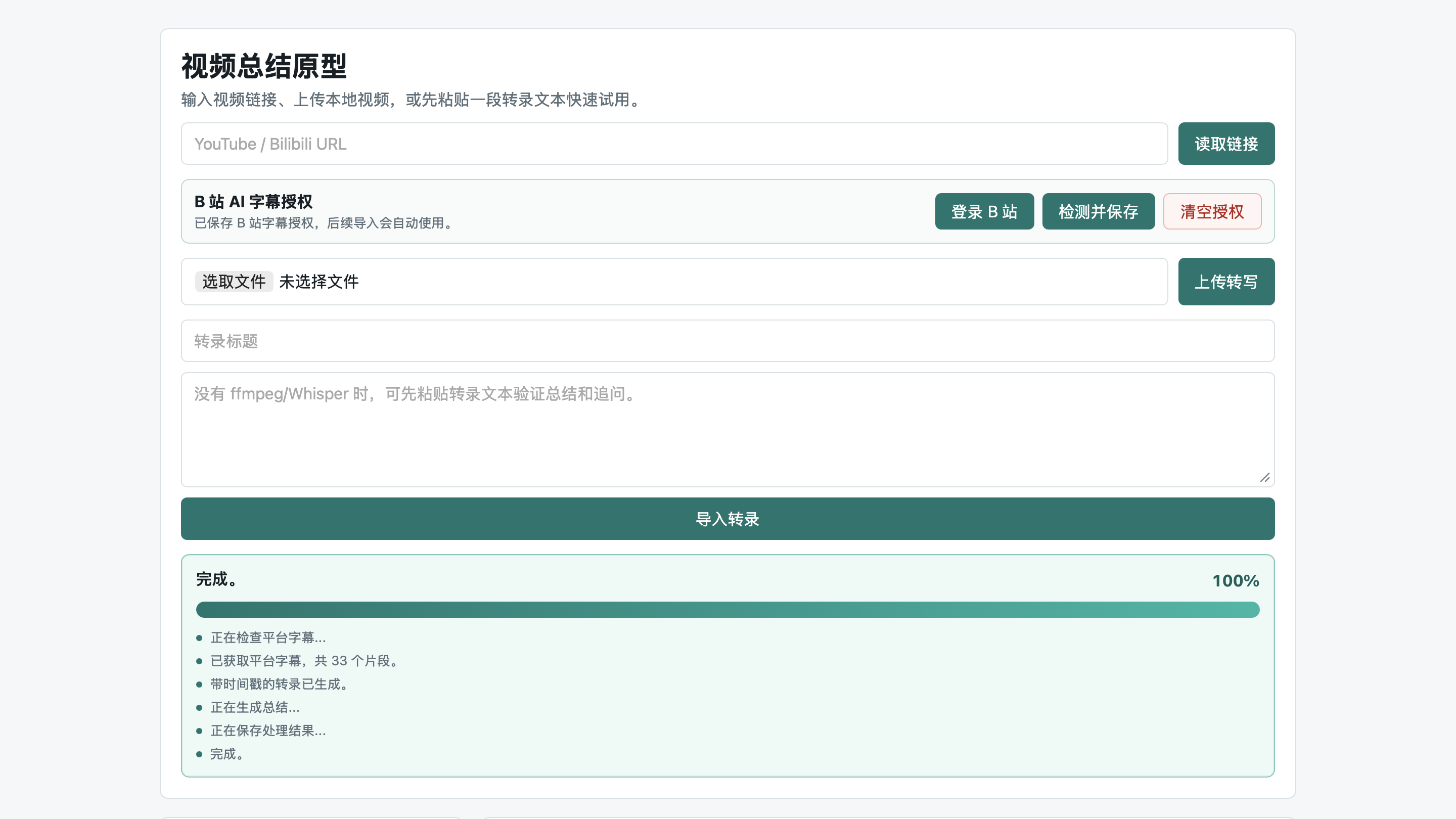
于是我开始做 Auto Video Summary。它现在还是一个 MVP,但核心链路已经跑通:输入视频链接或转录文本,系统读取字幕或生成字幕,再把视频整理成带时间戳的总结,并支持围绕视频内容继续提问。
我想解决的问题
我最初没有把它想成一个“AI 视频助手”这么大的产品,而是先把需求压缩成一句话:
给我一个视频,我想尽快知道它有没有必要花时间看。
这个目标决定了项目的第一版不需要很复杂。它不需要一上来就做账号系统、云端同步、多人协作,也不需要马上做漂亮的播放器。第一版只需要把一条链路做顺:
1 | 视频链接或本地内容 |
这里最关键的取舍是“字幕优先”。如果平台已经提供字幕,就没必要先下载音频再跑 Whisper。平台字幕通常更快,也能避免很多本地音视频解码问题。只有在没有字幕时,系统才退回到下载音频和自动转写。
这样做让 MVP 更实用:能快的时候尽量快,不能快的时候再走完整处理链路。
当前能做到什么
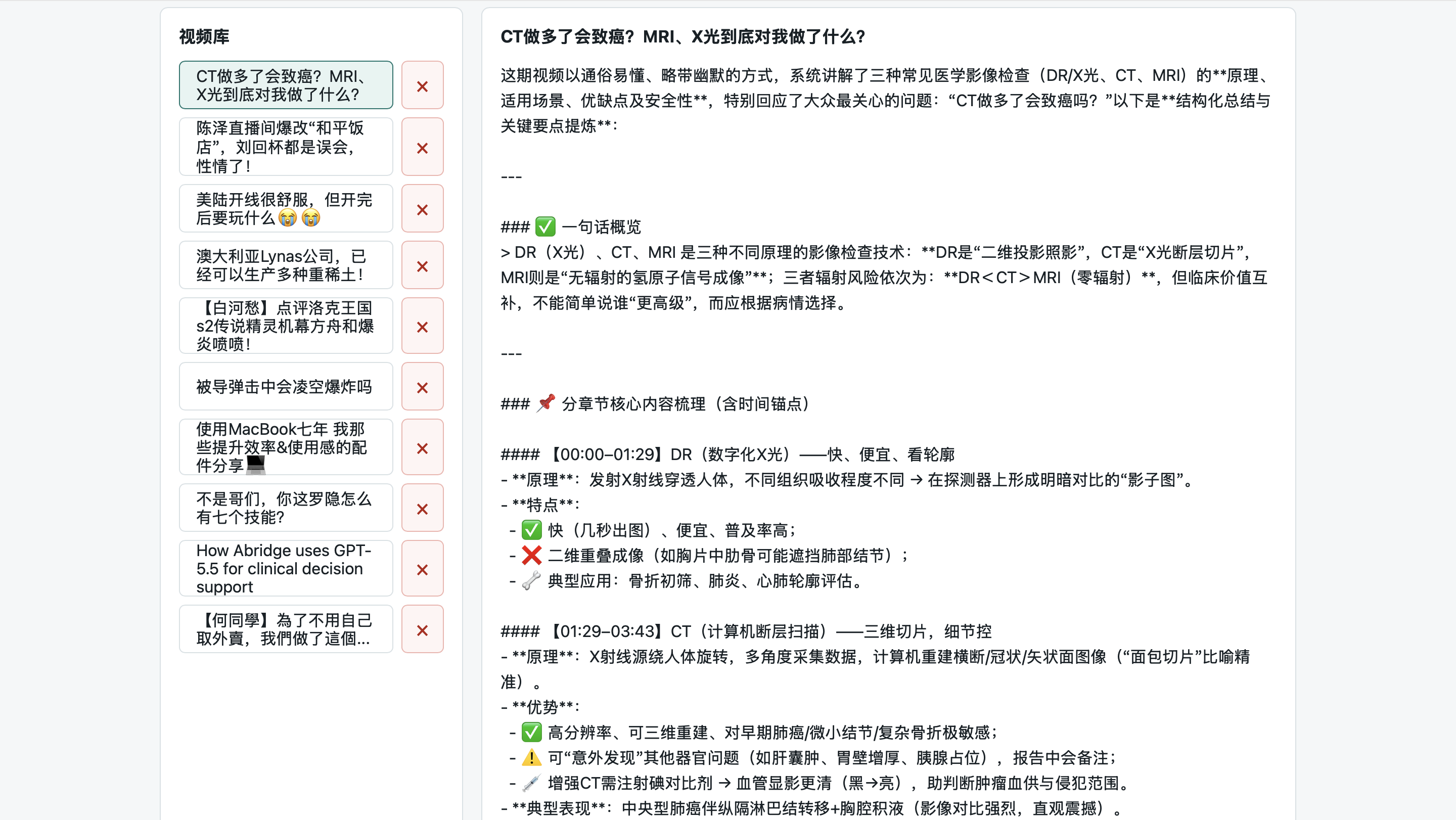
现在这个原型已经可以完成几类任务。
第一,读取 YouTube 和 Bilibili 链接。项目通过 yt-dlp 获取视频信息,并优先检查平台字幕。B 站这边还专门做了 AI 字幕授权入口,因为有些字幕需要登录态才能读取。
第二,读取或生成字幕。系统会优先使用平台字幕;如果没有可用字幕,就下载音频并交给 faster-whisper 转写,生成带时间戳的片段。
第三,导入已有转录文本。如果本机还没有配置 ffmpeg、Whisper,或者只是想先试一下总结和问答效果,也可以直接粘贴一段转录文本。
第四,生成总结。配置 OpenAI 兼容 API 后,系统会把转录片段送给模型,输出一句话概览、分章节要点、关键观点和可追问的问题。如果没有 API key,也会退化成本地抽取式总结,保证页面还能跑。
第五,围绕视频继续提问。用户选中一个视频后,可以基于转录内容追问。系统会先从视频片段里找相关依据,再让模型只根据这些依据回答,并在回答末尾列出时间戳。
这也是我觉得它有用的地方:总结不是最终答案,而是一个入口。先快速扫一眼,再围绕自己真正关心的问题追下去。
项目架构
项目现在的结构比较朴素,主要分成四层:
| 层级 | 负责内容 | 主要文件 |
|---|---|---|
| Web 前端 | 输入链接、上传文件、展示视频库、总结和追问 | web/index.html、web/app.js、web/styles.css |
| API 层 | 暴露导入、任务进度、视频记录、追问等接口 | app/main.py |
| 处理层 | 读取视频信息、下载字幕、转写音频、切分文本 | app/video.py、app/text_utils.py |
| 能力与数据层 | 调用 LLM、保存记录、管理配置和模型 | app/llm.py、app/storage.py、app/config.py、app/models.py |
整体流程大概是这样:
1 | 浏览器页面 |
我没有在第一版引入数据库,而是把记录存在本地 data/ 目录里:
1 | data/ |
这让项目在本地运行时很轻:不用先启动数据库,也不用配置额外服务。对于一个个人工具或原型来说,这种文件式存储足够直接。
后端:任务驱动的处理链路
后端用 FastAPI 写。API 层主要处理几件事:
POST /api/ingest/url:提交视频链接。POST /api/ingest/upload:上传本地音视频。POST /api/ingest/text:导入已有转录文本。GET /api/jobs/{job_id}:查询处理进度。GET /api/videos和GET /api/videos/{video_id}:读取视频库。POST /api/videos/{video_id}/ask:基于视频内容追问。
导入视频不是一个瞬间完成的请求,所以我把它抽象成任务。用户提交链接后,后端创建一个 IngestJob,前端轮询进度。任务过程中会持续更新状态,例如“正在读取视频信息”“正在检查平台字幕”“音频下载完成,正在转写”“正在生成总结”。
这一步看起来只是体验细节,但对视频处理很重要。因为视频任务经常要等待几十秒到几分钟,如果页面没有明确反馈,用户很难判断是卡住了,还是系统真的在处理。
字幕优先,再转写兜底
视频处理层在 app/video.py 里。这里最核心的逻辑是:
- 先用
yt-dlp获取视频信息。 - 检查平台字幕和自动字幕。
- 对 B 站链接额外尝试读取 AI 字幕接口。
- 如果拿到字幕,就解析成统一的
Segment。 - 如果没有字幕,再下载音频。
- 使用
faster-whisper转写音频。
Segment 是整个项目里很重要的数据结构:
1 | start: 开始时间 |
无论字幕来自 B 站、YouTube,还是 Whisper,最后都会被整理成同一种结构。这样后面的总结、检索和问答都不用关心字幕来源,只处理统一的时间片段。
B 站字幕这块比想象中麻烦。匿名访问时,有时只能看到弹幕或拿不到 AI 字幕,所以我加了一个“B 站 AI 字幕授权”流程:网页打开独立登录窗口,用户完成登录后,应用保存 cookies,后续导入 B 站链接时自动带上授权信息读取字幕。
LLM 层:总结与追问分开设计
LLM 相关逻辑集中在 app/llm.py。我把“总结”和“追问”拆成两个不同的提示词,因为它们的目标不一样。
总结时,模型要输出结构化内容:一句话概览、分章节要点、关键观点和可追问问题。这里我要求它只能基于转录,不要用外部知识扩写。
追问时,系统会先从转录片段中检索出和问题最相关的几段,再把这些片段作为依据交给模型。提示词同样要求模型只根据给定片段回答,不要把片段外的信息补进去。
这样做有两个好处:
第一,回答更容易追溯。用户不仅能看到答案,还能看到依据来自哪个时间段。
第二,可以降低幻觉。模型当然仍然可能犯错,但至少它被约束在视频片段范围内,不会随意把外部知识混进来。
目前相关片段检索还是关键词排序,不是向量检索。这是一个很典型的 MVP 取舍:先把问答链路跑通,再考虑更强的检索能力。
前端:先保证工作流完整
前端没有上复杂框架,就是一组静态文件。页面主要分成三个区域:
- 顶部导入区:链接、B 站授权、本地上传、文本导入。
- 左侧视频库:展示处理过的视频,可切换和删除。
- 右侧详情区:展示总结,并支持继续提问。
我优先做的是“能把流程走完”的界面,而不是一开始就追求视觉完成度。比如处理进度条、最近几步状态、任务取消、视频库删除,这些都是为了让真实使用更顺一些。
从截图也能看出来,当前 UI 仍然比较原型化。它可用,但还没有到我满意的程度。后续我会重点优化这一块。
现在的限制
这个版本能跑通核心功能,但限制也很明确。
第一,UI 还比较粗糙。它更像一个内部工具,还不像一个准备正式发布的产品。
第二,API 配置还不够友好。现在主要通过 .env 配置 OpenAI 兼容 API,对普通用户来说门槛偏高。
第三,本地视频能力还需要继续打磨。虽然代码里已经有上传转写链路,但还需要更好的错误提示、格式兼容性和处理体验。
第四,模型现在主要“读字幕”,还不能真正“看视频”。如果视频里大量信息来自画面、图表、演示操作或字幕之外的视觉细节,仅靠转录会漏掉不少东西。
第五,追问检索还比较基础。关键词检索能用,但对于长视频和复杂问题,后续应该换成向量检索或更细的片段索引。
后续更新计划
接下来我想按这个方向继续做:
- 优化 UI。让导入、进度、视频库、总结和追问更清晰,也让长内容阅读更舒服。
- 新增自主更换 API 的入口。用户可以在页面里配置模型服务、base URL、API key 和模型名,而不是必须改
.env。 - 完善本地视频总结功能。让用户可以更稳定地上传本地视频,自动抽取音频、转写、总结和追问。
- 添加图像识别能力。让模型能看到视频画面,而不仅仅是字幕。比如抽取关键帧、做 OCR、识别图表或操作界面,再和转录一起送给模型。
- 改进检索。用向量库替换当前关键词检索,让追问能更准确地找到相关片段。
- 增加时间戳跳转。回答里的依据可以直接跳到原视频对应位置。
- 支持批量任务。比如播放列表、B 站合集、课程目录等。
等这些能力更完善后,我会把项目发布到 GitHub。现在这个阶段,我更希望先把它打磨成一个自己每天愿意打开用的小工具。
写在最后
这个项目对我来说不是为了“用 AI 做一个很大的东西”,而是从一个很具体的痛点开始:长视频太多,注意力太贵,我需要一个先帮我看路标的工具。
做下来我也更明确了一件事:视频总结的难点不只是调用一次模型。真正麻烦的是前面的内容获取、字幕质量、登录态、音视频转写、任务进度、存储、追问依据,以及最后用户能不能自然地用起来。
Auto Video Summary 现在还只是原型,但它已经完成了最重要的一步:把视频从“只能从头看”的线性内容,变成了“可以先总结、再提问、按需深入”的资料。
后面我会继续把它往更完整的方向推。
更新:重新设计了 UI 界面
更新时间:2026-06-01 01:13:07
这次更新主要集中在界面重设计。相比最初那个更偏内部工具的原型,新版本开始把 Auto Video Summary 往“视频阅读室”的方向靠:少一点表单堆叠,多一点阅读、整理和追问的秩序感。
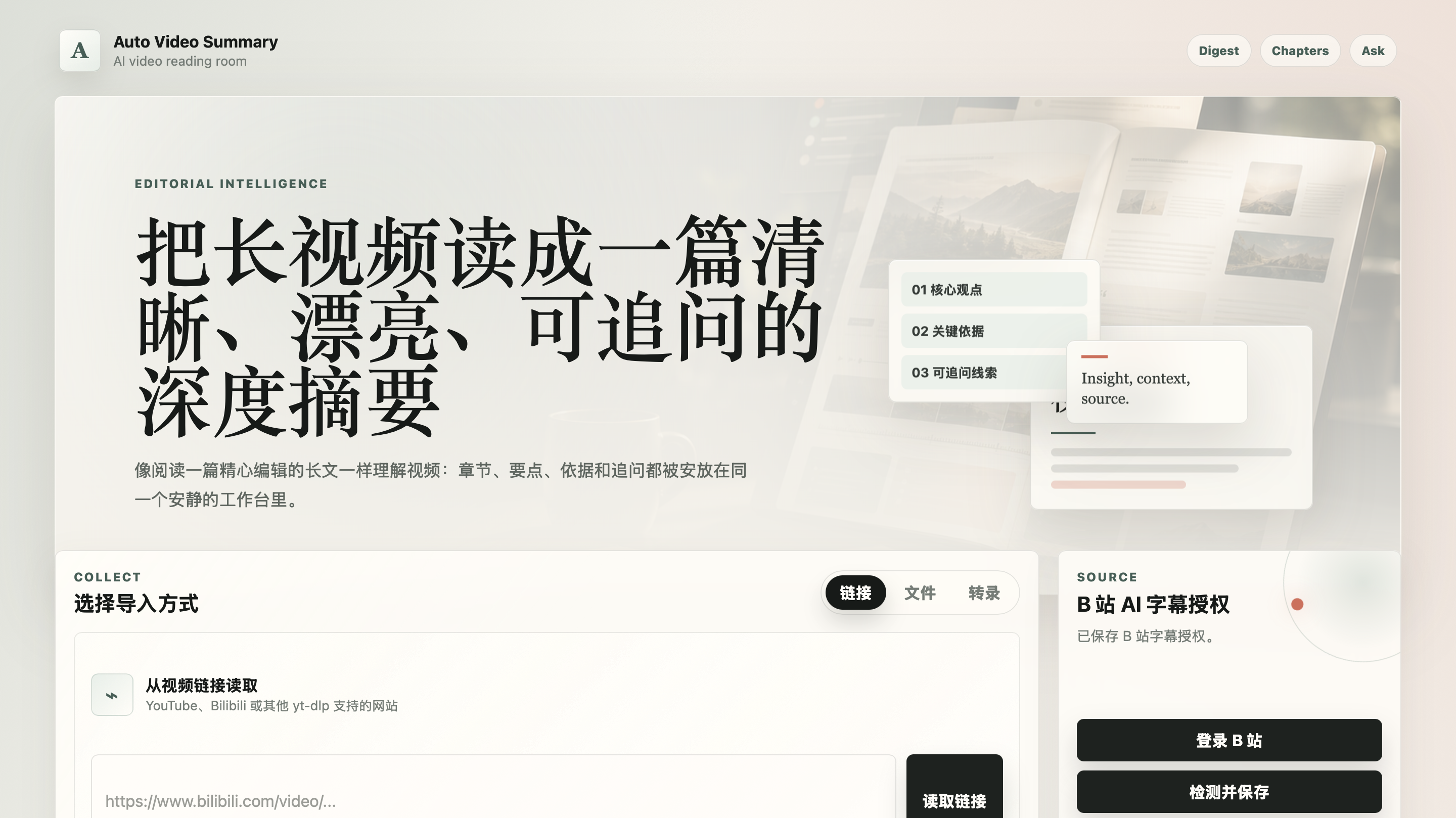
新的首页把导入流程放在更明确的位置,同时把链接、文件、转录三种入口收进同一个工作区里。顶部加入了更完整的品牌区和功能切换,页面整体也换成更安静的浅色背景、杂志感封面和更大的中文标题,让用户一打开就知道它不是单纯的字幕工具,而是一个用来“读视频”的工作台。
右侧的 B 站字幕授权也单独做成信息卡片。这个入口在功能上并不复杂,但它影响导入成功率,所以现在被放在更容易被注意到的位置:用户可以先确认授权状态,再读取需要登录态的字幕内容。
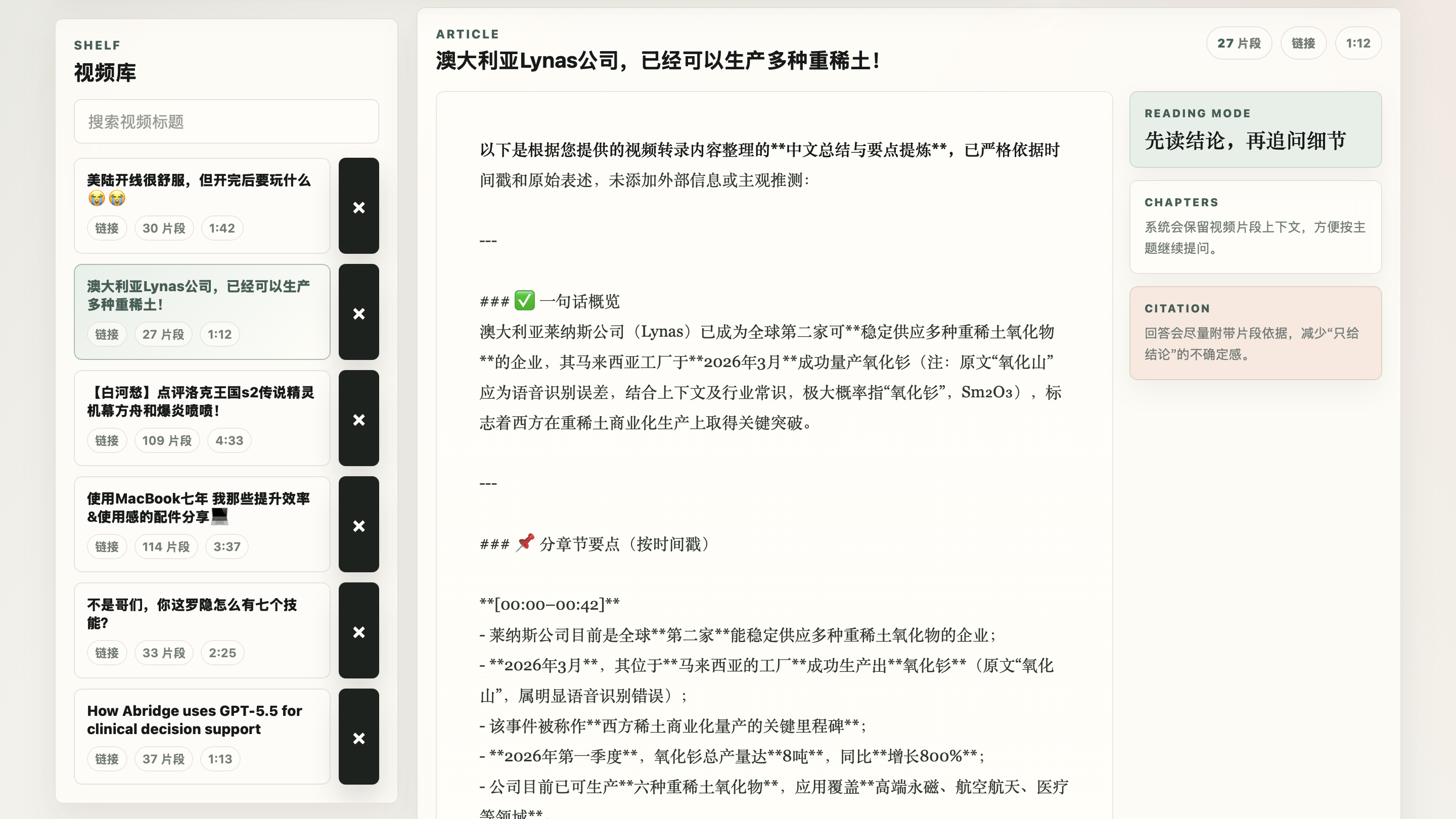
阅读页也重新整理了信息层级。左侧是视频库,中间是文章式总结,右侧保留阅读模式、章节和引用策略这些上下文提示。这样做之后,页面的重心从“我生成了一段文本”变成了“我正在阅读一篇由视频整理出来的文章”。
我尤其想保留的是可追问这件事的存在感,但不让它打断阅读。总结区先把结论、章节和依据按文章方式铺开,用户需要深入某个细节时,再通过右侧或顶部入口进入追问流程。对长视频来说,这种节奏更接近我真正想要的体验:先快速建立全局理解,再带着问题回到局部。
这次 UI 重设计还没有结束,后面还会继续补交互细节,比如更稳定的移动端布局、片段引用的跳转、追问记录的上下文管理,以及导入任务的状态反馈。但相比第一版,现在它已经更像一个我愿意长期打开使用的工具了。


